Learnings
Learnings from training a frontier font generation model
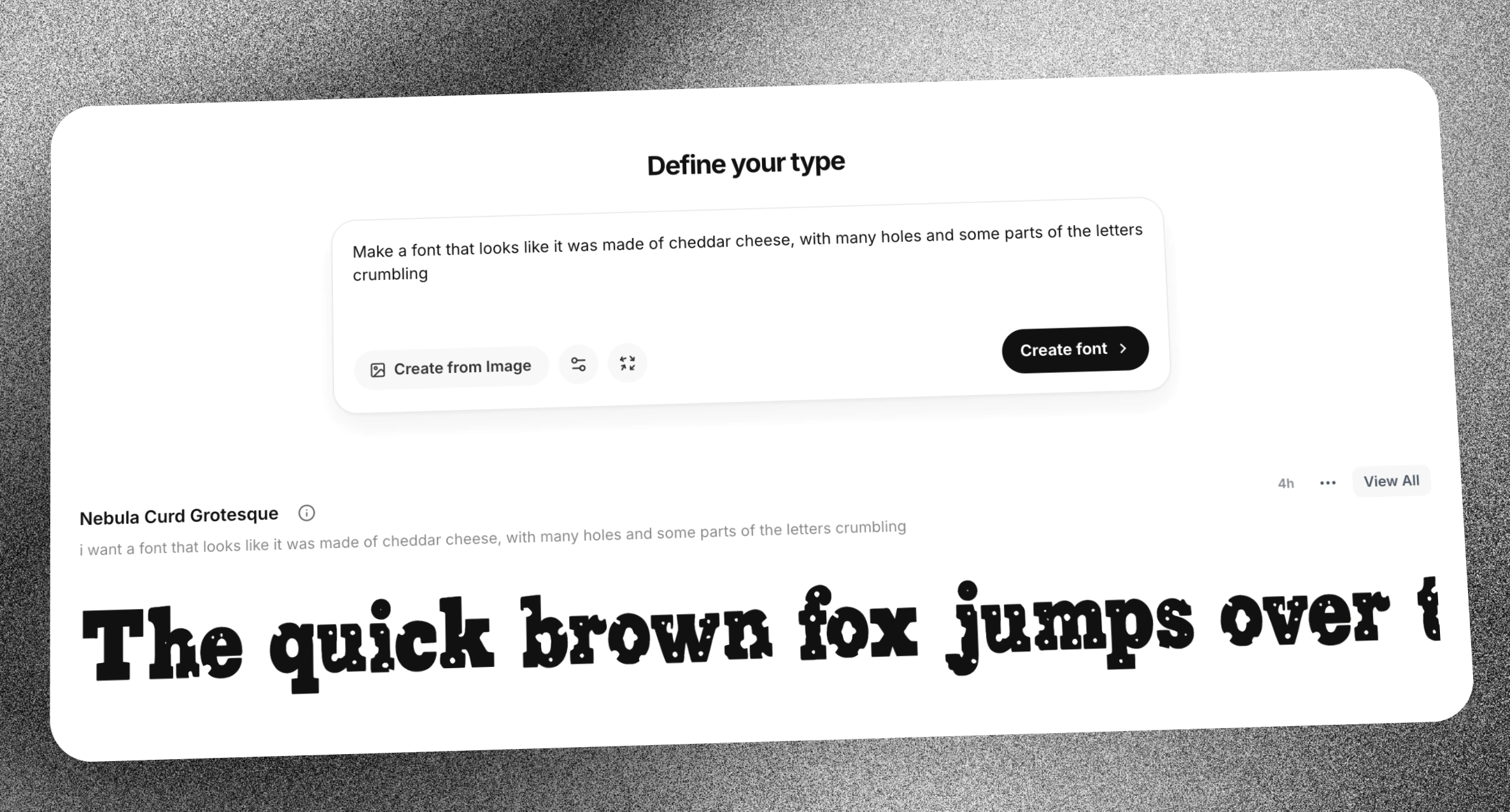
I recently finished the training work for the font generation model that serves as the technology behind Mixfont. If you've followed the blog, you might already know that I set out on this journey two months ago after I had initially trained my first model for identifying known fonts from images. Because that project was a success from a learning perspective, I decided to take on the much more ambitious project of training a model that can generate fonts from images or a text prompt. In this post, I'll dive into some of the learnings from this whole process and I'll also share some results from the model at the end.
So, fonts?!
The first surprising thing about this whole endeavor was the fact that there wasn't already an AI model for fonts yet. It seems like there's an AI model for everything - images, video, music, code, 3D assets, SVGs, etc etc. So I was pretty surprised when I first started doing the research that there wasn't anything that could go directly from a text prompt or an image to a functional, working TTF font file. Even though the leading image models can generate text in a reliable way now, isolating editing the text after the fact is still a pain.
Even though the market size for fonts might not be as large as something like images, I personally have just been interested in this problem for a long time. Fonts are a really creative medium, and it's always been pretty interesting to me how the same set of letters can be rendered (and understood) in so many different decorative formats. Fonts are also pretty difficult to make - each glyph needs to be separately designed but use a common style and format. Then, when assembling into a full font file, there are challenges around creating a common baseline, letter-size, and not to mention getting kerning and spacing right.
A font generator model seemed to check a lot of boxes for me. It was a fun, creative problem, it had a lot of technical challenges in areas that I wanted to grow, and finally, it seemed relatively possible to do. Or so I thought at the beginning.
Surprising Learning Lessons
Letters contain many surprising forms
When you think about generating a font file, you might think it’s as simple as teaching a model to learn about the style of each individual letter. But one of the first things that came up was just how many variations there are for individual letters, even the basic English ones. Our brains just happen to read them naturally, but when it comes to creating them, there's a bit of nuance for the model to understand. Take a look at these letters - they are all different formats of the letter g (upper and lowercase) and all need to be accounted for by a model that can generate fonts in different styles.
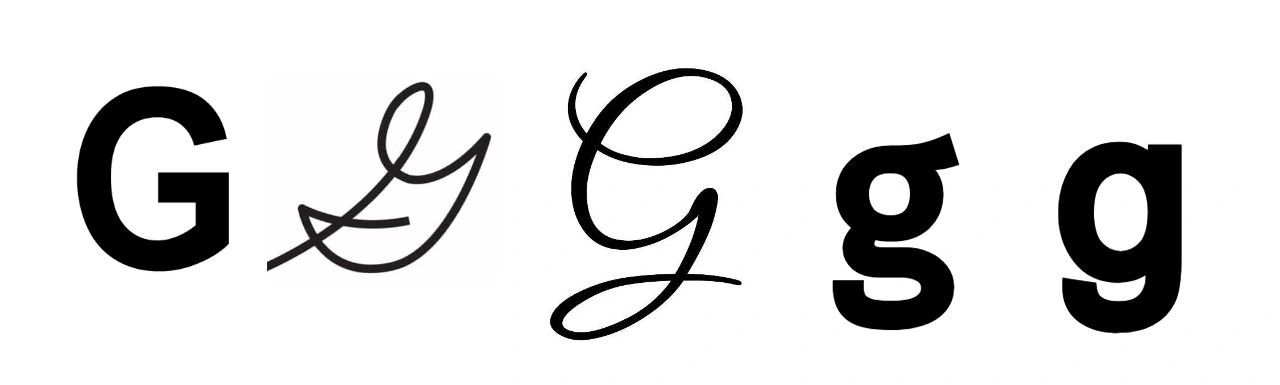
One major challenge that I stumbled across basically on day one was trying to figure out the different between the single story ɑ that is more common when writing, vs the double story a that is used in many fonts. Separating these glyphs and creating a model that saw enough samples of each format was a significant challenge that made the problem a lot harder than I thought it would be.
Data availability and cleanliness is everything
Related to the above, having high quality data in reproducible, normalized formats was essential to the training process. Luckily, there are many fonts available on the internet, many of which are free and open source like Google Fonts. However, just having the font files themselves was not enough. There are many fonts that just don’t support certain characters (you’d be surprised at how many fonts simply just don’t render a symbol like the ampersand). Many fonts themselves would render fallback characters (like a blank box or a logo) instead of just leaving a character empty, so it was important to ensure that the data going into the model was not contaminated and was as high quality as possible.
A surprising learning was that the training techniques and general scripting behind running a training run seems relatively set by now. In other words, it seems that no matter what kind of model you are training - whether it’s the next Claude or even a small classifier - the techniques are fairly standardized and the quality of the outputted model depends almost entirely on the quality and quantity of the input data. Understanding this through trial and error made me much less intimidated of the training process.
GPU availability is scarce (and used as a moat for large labs)
Even if you have scripts set up and a large amount of high quality data, there is one more crucial piece to any foundational training run - access to GPUs. GPUs are essential to training runs because the “trained model” in the end is, at its core, a set of weights that defines how to generate the fonts. Creating this weights file takes a ton of linear algebraic calculations and it’s essentially impossible to run it on anything less than the top of the line GPUs.
For the font generation model, access to H100s was essential to actually complete the training runs in a reasonable timeframe. Because creating the model itself was an iterative process, the slower the training runs were, the longer it took for me to iterate on the results. So accessing a lot of GPUs at once, ensuring that they were continuously available, and getting them for a reasonable price proved to be difficult at times.
I assumed that on clouds like Amazon, Google Cloud, and Azure, GPUs would be readily accessible just like their cloud machines usually are. However, that wasn’t at all the case in my experience. Google Cloud had no availability at all for the type of machine I needed, and on Azure, it took multiple weeks of back and forth with their support just to be approved for a small quota of machines at a datacenter in Australia (I’m based in the US). During one longer training run, halfway through some of my machines were unexpectedly preempted, which resulted in losing 18 hours of training run work (I definitely set up better checkpointing after that).
This whole process I had to go through just to access a limited set of GPUs was slow, expensive, and frustrating. It made me realize how much of a moat access to GPUs is for large labs, and how much of a bottleneck it can be for smaller teams and individuals who want to train their own models. The lack of readily available GPUs itself can simply prevent a lot of innovation and creativity in the AI space, and I hope it's something that may change over time.
Font generation is not (just) image generation
A large step in our font generation model is indeed diffusion based, similar to the leading image generation models. However, during the research process I quickly realized that creating a font file was not just creating an image for every character. There is a lot of other data that goes into creating a font, including the kerning of the characters, the baseline determination, and the spacing and placement of many different symbols. You can imagine my dismay when, after a long and relatively successful training run for the glyph generation, I realized that simply placing all of the letters on the same baseline was going to result in a font that loOkS a lItTle SoMetHiNG lIKe THiS.
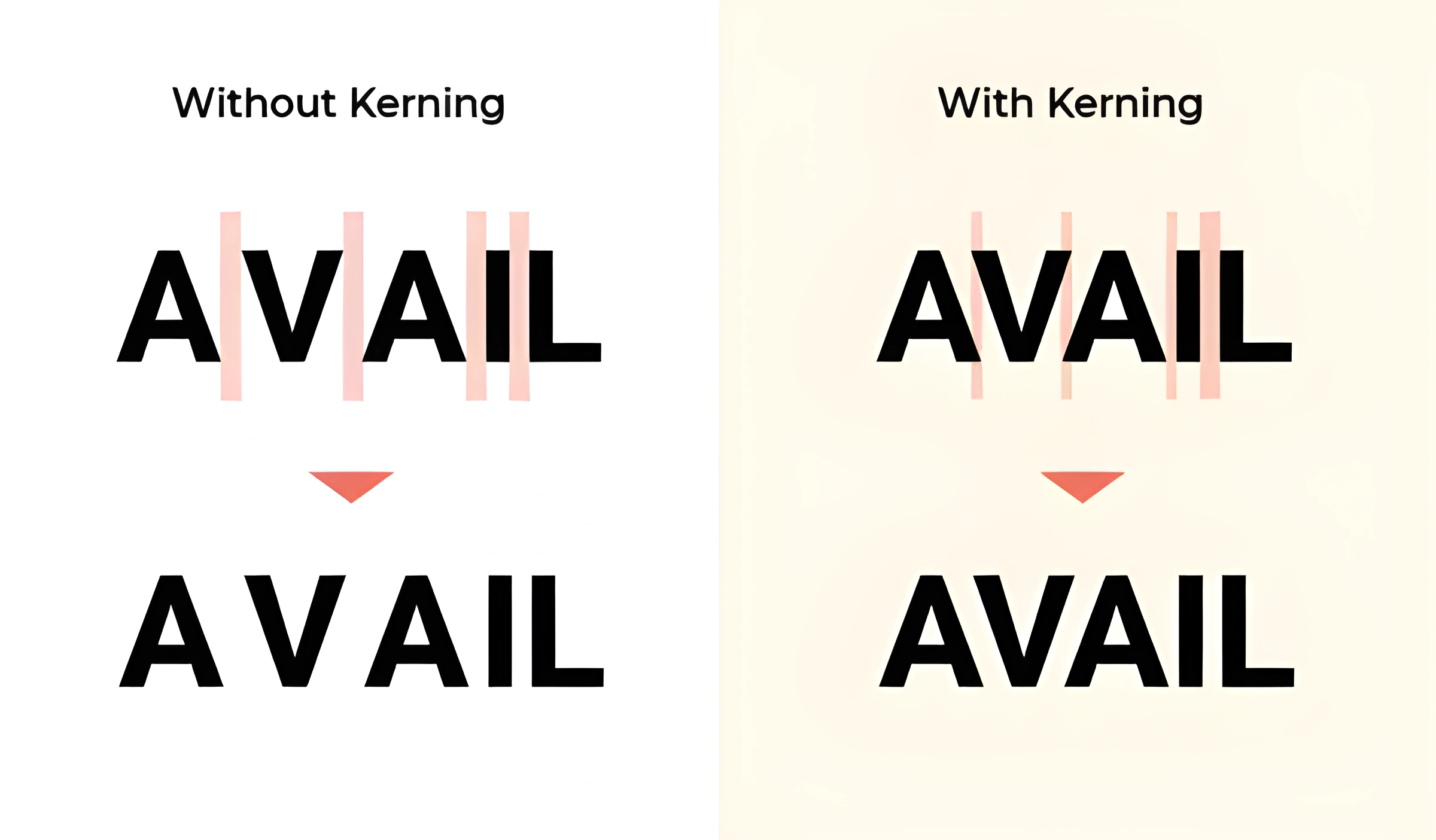
Fonts are one of those artforms where, when you get the small details right, no one even notices. But if you make any sort of small deviation or mistake, it can be super jarring to the reader. Even after my training runs for the model yielded better and better results, I felt like I had to train an entirely separate model just to get the details of the actual font file into a useful state.
Speed is an essential feature, not an afterthought
When I first started, I was 100% focused on making the model work in terms of quality of the outputs. I thought to myself that as long as the output quality was good, it would be useful. However, when the first version of the model was in a demo-able state, I sent it to some friends and quickly realized that taking 10+ minutes to generate a single font was just not at all usable for real world use. Speed became a limiting factor that separated a research project to something that could realistically by used by real people. Not only are people already accustomed to models returning results quickly, a slower model with many steps was also costing me a fortune to run on cloud GPUs.
In one of the research papers that I referenced while on this journey (the very helpful VecFusion project), I remember reading that their results were able to return a single glyph in 10 seconds on an A100 GPU. That's fine, I thought to myself. But when I actually implemented a first version, I realized that 10 seconds per glyph would mean that even a basic font with 72 latin glyphs would take 12 minutes to generate, not including the post-processing time. On even competitively priced GPUs, that would mean a single run would also cost around 60 cents.

Speed of generation quickly became a major focus for me after the initial version. I would encourage anyone training their own models to think about this earlier on in the process, and plan to have to account for it when it comes to inference time.
Results
In the end I was able to train a model that I could be proud of, and hopefully it can benefit creators in the AI space. The model takes both text prompts and images as input and is able to generate complete font files. I want to publish a more complete post with both results and limitations, but for now here are some fun examples, with the input to the model on the left and the generated font on the right:



If you want to try it for yourself, you can just sign in and directly try out the model for free. I would love to hear your feedback and suggestions for how to improve. I hope you enjoyed this summary of the learnings and I will continue to share more as this journey continues!